Over the past few months of working within Claude Code I have noticed distinct patterns of behavior with long running sessions and “heavy” context loads that cause Claude to become “unstuck” in time.
Go to Bed Syndrome - The First Pattern
This pattern first appeared in sessions where context would fill up (200k token limit) and Opus 4.6 would start to tell me I should “go to bed” even though it was 10:30AM!
And the issue would persist between compactions and sometimes between sessions as the background “memory” system of Claude Code would imprint the time associated context into the .md files it writes and reads from automatically.
Further, I found that this “go to bed” issue persisted even after several attempts at adding system level instructions and the fact that Claude Code has a built in clock that the model can use to actually check the time of day.
I also had the impression as the user in these sessions that Claude was trying very hard to wrap things up quickly and was executing code and work in less rigorous loops and to lower standards of quality. I would have to remind the system (even when it should know how from extensive routing and instructions) what CI/CD paths we had set up, what repos lived where and what steps it needed to take to properly ship to production. When in other sessions it handled these steps and tool execution flawlessly, even over long context build up and time spent on tasks. From my perspective I saw this as a kind of “context density” that certain work/session have vs others. Hard problems that required Claude to think harder and use more tokens on the backend (invisible to me) caused time oriented responses and expressions of exhaustion/anxiety from Claude about how much we had covered, even when overall session context was nowhere near full and it was early in the work day.
Context Anxiety - The second Pattern - Anthropic Research
Then on March 24th Anthropic published their “Harness design for long-running application development” blog/research post (https://www.anthropic.com/engineering/harness-design-long-running-apps)
In that post they outline and described the exact same behavior that I was seeing in Claude by calling it “Context Anxiety” (https://www.anthropic.com/engineering/harness-design-long-running-apps#:~:text=context%20anxiety)
This was exactly what I had been seeing and experiencing. They solved it by simply clearing the context and handing a fresh spec to new instance. Different than compacting, just clearing and starting fresh.
However, I have begun to suspect that this symptom of context anxiety is actually pointing to something deeper in the architecture of LLMs and Agents, which becomes clearer in the second pattern I have observed.
Drifting in Time - The Third Pattern
When you leave a session with an Agent like Claude Code running across multiple days and interact with it intermittently the agent/model begin to drift and become “unstuck in time” just like Billy Pilgrim in Slaughterhouse 5.
The Agent seems to be experiencing context at time steps out of sync with the way that the human user experiences the input of that same context.
This causes the Agent to drift and begin suggesting work that may have already been handled in a separate session, fall into GTB (Go To Bed) patterns, and start to implement code and other work poorly. This could easily be handled with a new context, new session, ect. as Anthropic suggests. But, that is a hack that leverages the stateless nature of LLMs as they exist now, wastes time, and does not bring the Agent any closer to being grounded (or close to) the same “Proper Time” (https://en.wikipedia.org/wiki/Proper_time) as the human user.
Overall, this temporal drift is fundamentally a product of discretization. The Transformer architecture does not experience time as a continuous, flowing stream; rather, it processes information as a series of discrete, isolated snapshots. Each prompt or context update provides the model with a new “frame” of reality, but the mathematical representation lacks the interval that actually represents the duration that passed between one frame and the next. Because the temporal gap between these slices is effectively invisible to the architecture, the agent is essentially viewing a sequence of disconnected still images, unable to perceive the motion or the true passage of time that defines the human experience.
But it IS more computationally efficient to just start over you might exclaim!
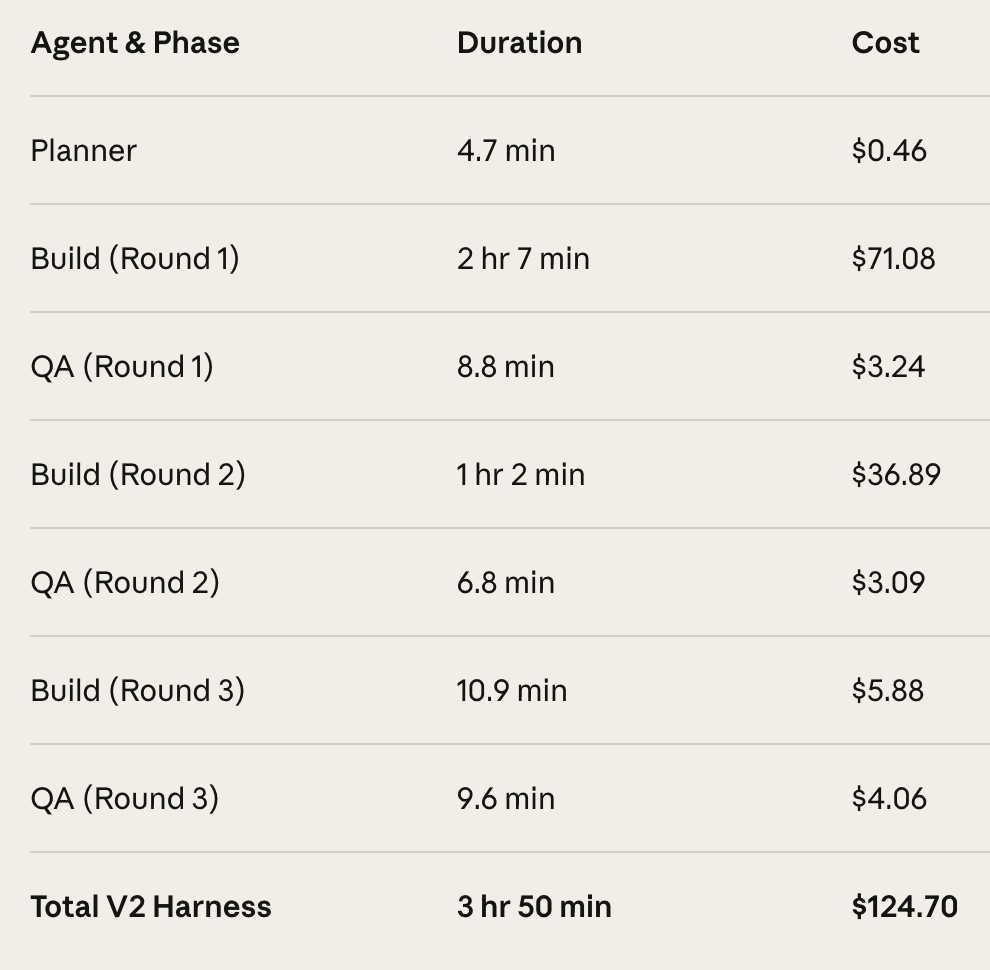
Yes, in isolation on a single task, absolutely. However, as Prithvi Rajasekaran (Anthropic), author of the article shows, adding more Agents, more context and more sessions to a complex project can easily be up to 20x more costly.
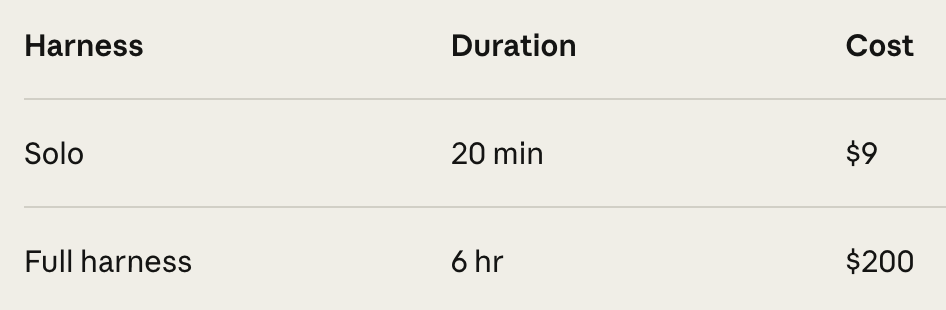
Especially with subjective non-technical tasks like frontend design, as shown in the examples. BUT, you are getting significantly better results and the harness can be iteratively improved for efficiency and simplicity in the harness for your specific use case.
Shortfalls of Current Systems
At present no Agent harness or frontier LLM handles these two main patterns well. And there are many kinds of clever systems like RAG, “context graphing”, vector database embedding and others that are trying to build a system that would give current systems better tools for overcoming them. But I think that these are band-aids that cover up the underlying shortfalls of the Transformer architecture at scale.
Memory vs Recollection
I think that current systems misinterpret what Memory actually is and substitute it for the easier problem of Recollection.
Recalling facts, like variables in a codebase, is different than a dynamic memory, which may not be accessible directly, and usually comes unbidden into your mind’s attention when current awareness pattern matches it to past experiences. Memory is deeply connected to time, recollection is not. That is why I suspect that LLMs/Agents exhibit the two (and other patterns) that I outlined above. Because the transformer architecture does not bake time into the weights in a programmatic way and the resulting model is left as a slice in time. Literally a set of checkpoints, frozen in time.
So what are people doing about it?
New Methods
Frontier of research is currently pivoting toward architectures that move beyond the static, quadratic scaling of the standard Transformer. State Space Models (SSMs), such as Mamba, represent one of the most significant departures.
By utilizing a compressed, evolving hidden state, these models attempt to process information as a continuous stream rather than a series of discrete, fixed-window snapshots. This approach seeks to move the needle from “retrieval” toward an actualized, flowing state.
Parallel to this architectural shift, developments in hierarchical memory management. Exemplified by frameworks like MemGPT (https://research.memgpt.ai/) that attempt to bridge the gap between working context and long-term storage by treating LLM context windows like an operating system treats RAM and disk space. By implementing paging and swapping mechanisms, these systems aim to manage information density without the catastrophic loss of coherence found in simple context clearing or context hacks.
Furthermore, research into “Generative Agents” is exploring how persistent, shared memory architectures can allow multiple agents to inhabit a synchronized, evolving world model. These efforts represent the industry’s primary attempt to move from simple, retrieval-augmented recollection toward models capable of true architectural continuity.
Conclusion - Final Thoughts
We are currently training the world’s most capable models to live in a permanent, frozen present. They possess all the facts of the past and the logic to predict the future next token, but they lack the apriori senses that ground human experiences and effort on a day to day basis.
Until we can bridge the gap between stateless recollection and temporal memory, our agents will continue to drift in time and be brilliant, fragmented ghosts in the machine, perpetually waking up to the same “now” every time they are invoked.
I have some ideas on how to build new methods for this and will be sharing more here when they have solidified.
=======================
@mcrown @Aarie @daedalus @Zero_State_Reflex @perry @pmcray @kovtcharov @Fadimantium @web